
Các Cập Nhật Mới Google Cloud Open Lakehouse
Google Data Cloud là nền tảng tích hợp tiên tiến, được xây dựng trên hạ tầng toàn cầu của Google, tích hợp sâu AI và nổi bật với kiến trúc open lakehouse, hỗ trợ dữ liệu đa phương thức. Nhiều doanh nghiệp hàng đầu đã chứng minh hiệu quả vượt trội của Google Data Cloud trong việc tối ưu hóa khai thác dữ liệu, nâng cao hiệu suất cho đội ngũ kỹ sư và nhà khoa học dữ liệu. Hiện nay, Google Data Cloud tiếp tục mở rộng năng lực với loạt cải tiến đột phá cho giải pháp lakehouse hỗ trợ bởi AI. Hãy cùng Cloud Ace tìm hiểu nhé.
Mở rộng BigLake: Nền tảng dữ liệu hợp nhất, mở và linh hoạt cho doanh nghiệp
BigLake đang được phát triển thành một môi trường runtime lưu trữ toàn diện cho Google Data Cloud, tận dụng Google Cloud Storage. Điều này cho phép doanh nghiệp xây dựng các lakehouse hiệu suất cao, được quản lý, mở rộng trên cả bộ nhớ gốc của Google và dữ liệu định dạng mở.
Các cải tiến đáng chú ý như:
- 🔹 Iceberg native storage: Cung cấp tính năng lưu trữ cấp doanh nghiệp cho Iceberg với BigLake tables for Apache Iceberg (GA).Tính năng này tích hợp khả năng quản lý của Google Cloud Storage, cho phép sử dụng Autoclass để tối ưu hóa phân tầng dữ liệu và áp dụng các khóa mã hóa do khách hàng quản lý (CMEK).
- 🔹 Quản trị tập trung: BigLake được hỗ trợ trong Dataplex Universal Catalog, đảm bảo quản trị dữ liệu nhất quán trên toàn bộ hệ thống.
- 🔹 BigLake Metastore (GA) và Apache Iceberg REST Catalog API (Preview): Cung cấp một giải pháp siêu dữ liệu hợp nhất, được quản lý, phi máy chủ và có khả năng mở rộng. Nền tảng này hỗ trợ phân tích, truy vấn vận hành, truyền phát và AI trên dữ liệu từ BigQuery, Iceberg native storage và các định dạng mở tự quản lý, thúc đẩy khả năng tương tác công cụ phổ quát với các dịch vụ của Google Cloud (BigQuery, AlloyDB, Google Cloud Serverless for Apache Spark) và các công cụ bên thứ ba, mã nguồn mở.
- 🔹 Dịch vụ di chuyển dữ liệu nâng cao: Đơn giản hóa việc đưa dữ liệu vào Iceberg native storage thông qua Iceberg table và metadata migration from Hadoop/Cloudera (Preview) và dịch vụ Delta to Iceberg (Preview).
Hợp nhất Công cụ Phân tích và Vận hành trên Dữ liệu Mở
BigQuery có thể đọc và ghi dữ liệu Iceberg thông qua BigLake tables for Apache Iceberg, mang lại khả năng phân tích chuyên sâu. BigQuery còn tăng cường các Iceberg tables với các tính năng cao cấp như: truyền tải dữ liệu thông lượng cao cho truy vấn không độ trễ, quản lý bảng nâng cao với tự động sắp xếp lại dữ liệu, và hỗ trợ multi-table transactions (Preview) cho các trường hợp sử dụng ETL phức tạp. Doanh nghiệp cũng có thể tận dụng các khả năng AI tích hợp của BigQuery (BQML, AI Query Engine, multimodal analysis) trực tiếp trên dataset mở. Sự tích hợp này mang lại lợi ích từ tính mở và quyền sở hữu dữ liệu của ative Iceberg storage, đồng thời khai thác khả năng mở rộng của BigQuery. Thực tế, việc sử dụng BigLake Iceberg với BigQuery của khách hàng đã tăng gần gấp 3 lần trong 18 tháng, quản lý hàng trăm petabyte
Khả năng quản lý dữ liệu hợp nhất mở rộng đến các hoạt động kinh doanh cốt lõi với AlloyDB for PostgreSQL, cơ sở dữ liệu hoạt động hiệu suất cao. AlloyDB giờ đây có thể truy vấn trực tiếp dữ liệu Iceberg được quản lý bởi BigLake. Điều này cho phép các ứng dụng nghiệp vụ khai thác dữ liệu phong phú từ BigLake mà không cần ETL phức tạp, đồng thời áp dụng các khả năng AI của AlloyDB như tìm kiếm ngữ nghĩa và truy vấn ngôn ngữ tự nhiên trên dữ liệu Iceberg.

Tối đa hóa sức mạnh của BigQuery SQL và Spark Serverless trên dữ liệu mở
Tăng cường hiệu suất BigQuery SQL: Công cụ SQL của BigQuery được tích hợp một loạt các cải tiến hiệu suất tự động độc đáo:
- BigQuery advanced runtime (Preview): Tự động tăng tốc khối lượng công việc phân tích bằng cách sử dụng tính năng vector hóa nâng cao và chế độ tối ưu hóa truy vấn ngắn, không yêu cầu hành động hay thay đổi code từ phía người dùng.
- BigQuery API optional job creation mode (GA): Tối ưu hóa querry path cho các truy vấn tương tác, thời lượng ngắn, giảm độ trễ đáng kể.
- BigQuery column metadata index (CMETA) (GA): xử lý truy vấn trên các bảng dữ liệu lớn, bằng cách tự động lọc bớt dữ liệu không cần thiết, giúp hệ thống xử lý nhanh và hiệu quả hơn.
- BigQuery fine-grained updates/deletes (Preview): được cải tiến để hoạt động nhanh hơn gấp nhiều lần, giúp doanh nghiệp linh hoạt hơn trong việc xử lý khối lượng dữ liệu lớn, kể cả trên các định dạng dữ liệu mở.
Lightning Engine (bản Preview) tăng tốc hiệu suất Apache Spark lên đến 3.6 lần nhờ kết nối tối ưu với Cloud Storage, BigQuery, cơ chế shuffle cột hiệu quả và bộ nhớ đệm thông minh. Sử dụng native C++ libraries (Velox and Gluten), và hỗ trợ vector hóa, Lightning Engine giúp xử lý dữ liệu nhanh chóng, mạnh mẽ.
Giải pháp Spark AI/ML-ready, tích hợp thư viện AI có sẵn, runtime ML mới và hỗ trợ GPU, sẵn sàng triển khai qua Serverless for Apache Spark hoặc Dataproc, phù hợp cho kiến trúc lakehouse doanh nghiệp.
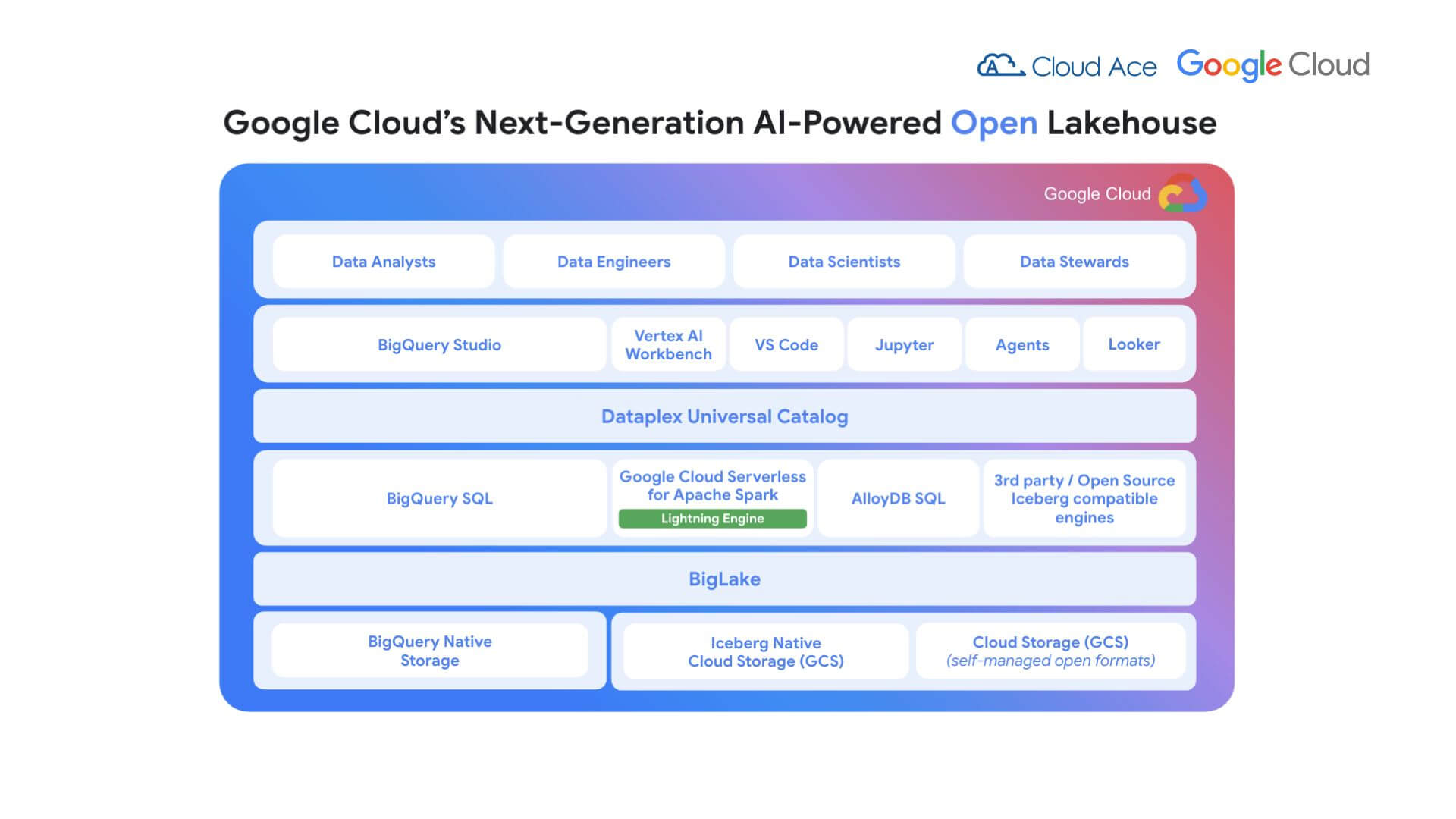
Dataplex Universal Catalog
Dataplex Universal Catalog (DUC) mang đến một hệ thống danh mục thông minh, tự động phát hiện, hiểu và tổ chức metadata trên toàn bộ dữ liệu phân tán: từ BigQuery, Cloud Storage (Iceberg, Delta, Hudi), cơ sở dữ liệu giao dịch như Spanner, đến mô hình ML trong Vertex AI.
DUC cho phép doanh nghiệp xây dựng và áp dụng chính sách quản trị tập trung với quyền truy cập chi tiết trên nhiều công cụ xử lý dữ liệu thông qua BigLake. Tính năng credential vending giúp mở rộng chính sách đến dữ liệu lưu trữ một cách an toàn.
Được tăng cường bởi AI và Gemini, DUC biến metadata thành nguồn tri thức động: tự động quản lý metadata, suy luận mối quan hệ ẩn, đề xuất phân tích từ các truy vấn phức tạp và hỗ trợ tìm kiếm ngữ nghĩa bằng ngôn ngữ tự nhiên.
Kết quả: Độ chính xác khi xác định dataset tăng 50%, rút ngắn thời gian tìm kiếm insight. DUC còn hỗ trợ tích hợp mở với các nền tảng như Collibra và kết nối linh hoạt thông qua API.
Google Cloud mang AI và Lakehouse tích hợp vào quy trình làm việc của data developer
Mục tiêu của Google Cloud là tái định hình trải nghiệm dữ liệu bằng cách tích hợp AI và lakehouse trực tiếp vào các công cụ và quy trình làm việc quen thuộc giúp các đội ngũ gia tăng năng suất và đổi mới nhanh chóng.
Trọng tâm là BigQuery Notebooks thế hệ mới, hỗ trợ AI mạnh mẽ, cho phép phát triển thống nhất trên SQL, Python và Apache Spark. Tính năng tích hợp Gemini đóng vai trò cộng tác viên thông minh, hỗ trợ tạo code PySpark nâng cao, giải thích các code phức tạp và khắc phục sự cố Spark không máy chủ (Preview), giúp rút ngắn đáng kể thời gian từ dữ liệu đến insight.
Ngoài ra, các tiện ích mở rộng mới cho JupyterLab và Visual Studio Code hỗ trợ BigQuery, Dataproc và Serverless Spark Preview), giúp kết nối nhanh với nền tảng lakehouse mở của Google Cloud ngay trong IDE quen thuộc.
Facebook
Linkedin
Cloud Ace - Managed Service Partner của Google Cloud
- Trụ sở: Tòa Nhà H3, Lầu 1, 384 Hoàng Diệu, Phường 9, Quận 4, TP. HCM.
- Văn phòng đại diện: Tầng 2, 25t2 Hoàng Đạo Thúy, Phường Trung Hoà, Quận Cầu Giấy, Thành phố Hà Nội.
- Email: sales.vn@cloud-ace.com
- Hotline: 028 6686 3323
- Website: https://cloud-ace.vn/
