Data là điều cần thiết cho bất kỳ ứng dụng nào và được thiết kế trong một hệ thống pipeline để quản lý toàn bộ thông tin của tổ chức, doanh nghiệp. Vì vậy, việc xác định đường dẫn dữ liệu (data pipeline) là điều quan trọng trong việc phân tích và ứng dụng data để mở rộng kinh doanh. Bài viết dưới đây Cloud Ace sẽ giúp người dùng hiểu rõ họ nên sử dụng kiến trúc data pipeline nào trong Google Cloud Platform.
1. GCP Data Pipeline
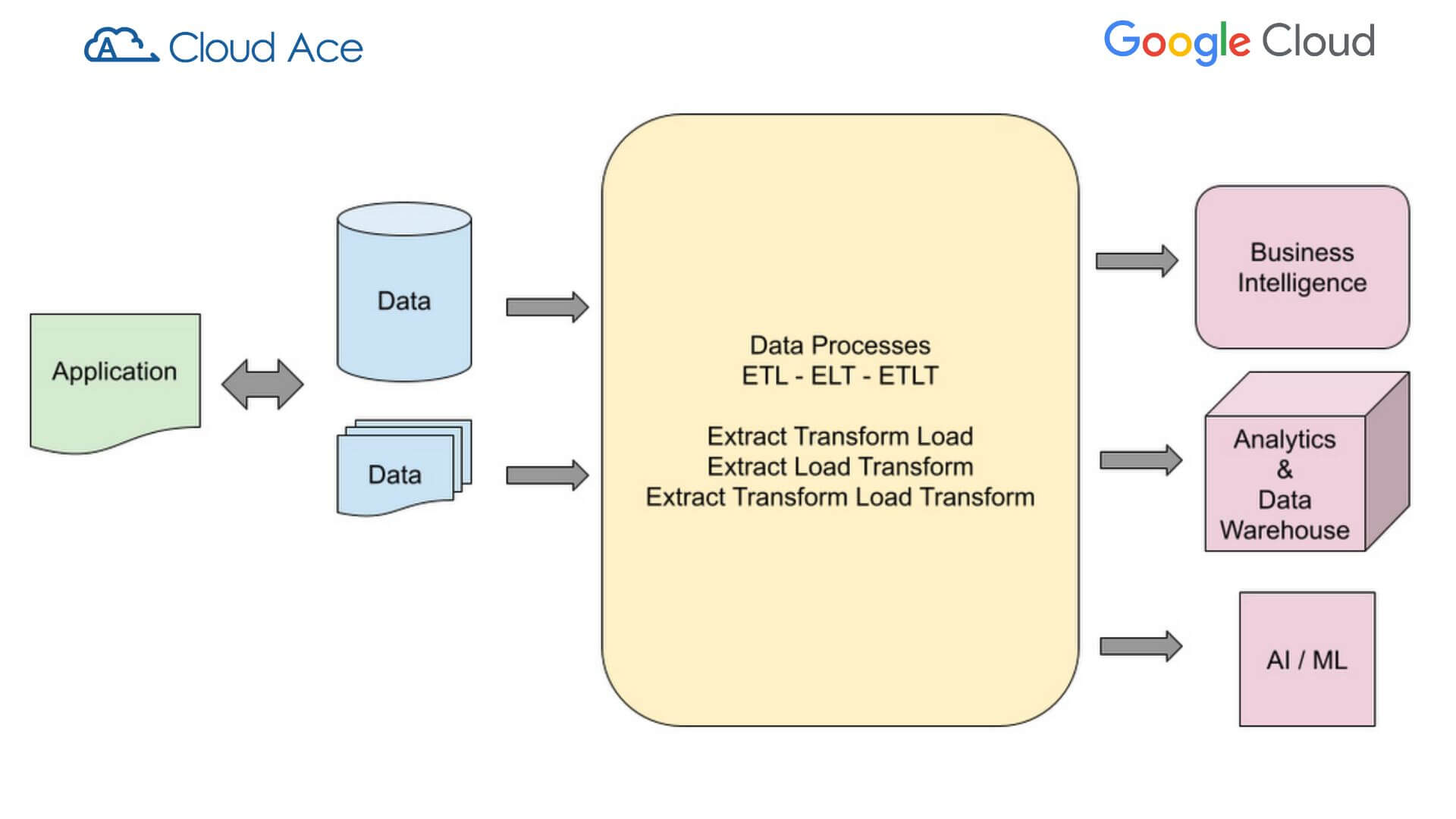
Data Pipeline (đường dẫn dữ liệu) có thể bắt đầu ở nơi dữ liệu được tạo và lưu trữ bởi bất kỳ định dạng nào, và kết thúc bằng việc dữ liệu được phân tích, lưu trữ, xử lý qua mô hình máy học và được sử dụng để mở rộng kinh doanh.
Dữ liệu được trích xuất, xử lý và chuyển đổi theo nhiều bước tùy thuộc vào yêu cầu hệ thống. Mọi bước xử lý và chuyển đổi đều được xác định trong data pipeline.
2. Làm thế nào để chọn mẫu thiết kế cho Data Pipeline?
2.2 Các mẫu thiết kế của GCP Data Pipeline
Khi chọn một mẫu thiết kế đường dẫn dữ liệu, có các yếu tố khác nhau phải được xem xét. Các yếu tố này bao gồm:
Chọn định dạng nguồn dữ liệu.
Chọn các ngăn nào sẽ sử dụng.
Chọn công cụ chuyển đổi dữ liệu.
Chọn giữa Extract Transform Load (ETL), Extract Load Transform (ELT), hoặc Extract Transform Load Transform (ETLT).
Xác định các dữ liệu đã thay đổi được quản lý.
Xác định cách các thay đổi được nắm bắt.
Các bước xử lý và trình tự của luồng dữ liệu là những yếu tố chính ảnh hưởng đến thiết kế data pipeline. Mỗi bước có thể bao gồm một hoặc nhiều đầu vào dữ liệu, và đầu ra có thể bao gồm một hoặc nhiều giai đoạn.
Quá trình xử lý giữa đầu vào và đầu ra có thể bao gồm các bước biến đổi đơn giản hoặc phức tạp. Vì vậy, việc giữ cho thiết kế data pipeline đơn giản và theo mô-đun giúp nhóm developers thực hiện các chu kỳ phát triển và triển khai dễ dàng hơn. Nó cũng giúp gỡ lỗi và khắc phục sự cố dễ dàng hơn.
2.2 Các thành phần chính Data Pipeline
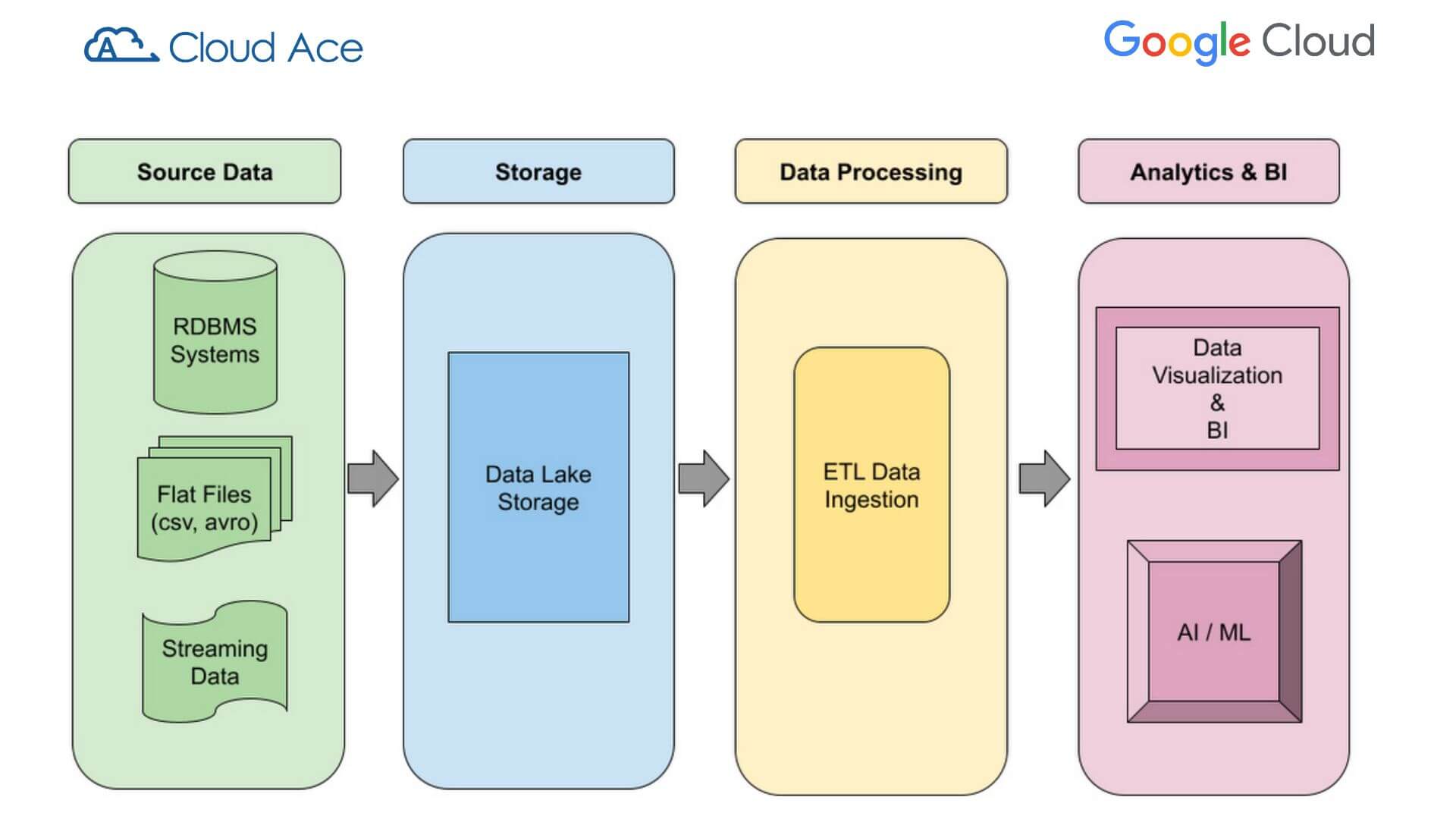
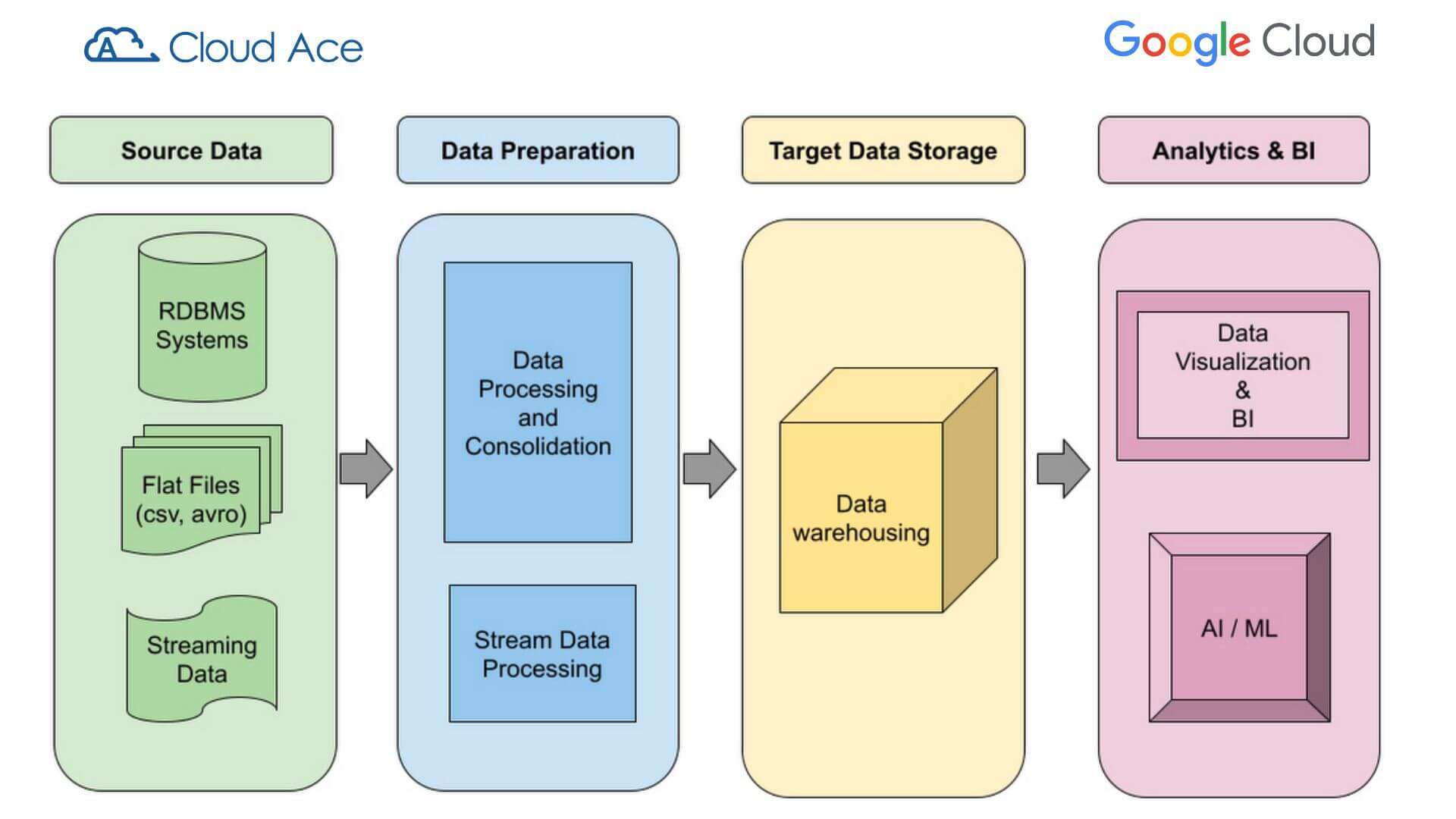
Source Data: có thể là ứng dụng giao dịch, tệp được thu thập từ người dùng và dữ liệu được trích xuất từ API bên ngoài.
Processing: xử lý dữ liệu nguồn có thể đơn giản như sao chép một bước hoặc phức tạp như nhiều phép biến đổi và kết hợp với các nguồn dữ liệu khác.
Target Data: Hệ thống kho dữ liệu đích có thể yêu cầu dữ liệu được xử lý là kết quả của quá trình chuyển đổi (chẳng hạn như thay đổi kiểu dữ liệu hoặc trích xuất dữ liệu) cũng như tra cứu và cập nhật từ các hệ thống khác.
Source Data có thể được trình bày ở nhiều định dạng. Có thể có nhiều loại dữ liệu được yêu cầu trong một data pipeline như:
Batch Data: Một tệp có thông tin dạng bảng (CSV, JSON, AVRO, PARQUET, etc) trong đó dữ liệu được thu thập theo ngưỡng hoặc tần suất xác định với xử lý theo conventional batch hoặc xử lý theo micro-batch. Các ứng dụng hiện đại có xu hướng tạo dữ liệu liên tục. Vì lý do này, xử lý micro-batch là một thiết kế được ưu tiên để thu thập dữ liệu từ các nguồn.
Transactions Data: Dữ liệu ứng dụng như RDBMS (dữ liệu quan hệ), NoSQL, Dữ liệu lớn.
Stream Data: Các ứng dụng thời gian thực sử dụng Kafka, Google Pub/Sub, Azure Stream Analytics hoặc Amazon Stream Data. Các ứng dụng stream data có thể giao tiếp real-time và trao đổi thông điệp để đáp ứng các yêu cầu. Trong thiết kế kiến trúc doanh nghiệp, xử lý luồng và thời gian thực là một thành phần rất quan trọng của thiết kế.
Flat file PDF hoặc các định dạng không phải dạng bảng có chứa dữ liệu để xử lý. Ví dụ: các tài liệu y tế hoặc pháp lý có thể được sử dụng để trích xuất thông tin.
Target Data (dữ liệu mục tiêu) được xác định dựa trên các yêu cầu và nhu cầu xử lý downstream. Việc xây dựng target data để đáp ứng nhu cầu cho nhiều hệ thống là điều phổ biến.
3. Data Pipeline Architecture
Kiến trúc đường ống dữ liệu có thể được chia thành các level Logical và Platform.
Logical Level: mô tả cách dữ liệu được xử lý và chuyển đổi từ nguồn sang đích.
Platform Level: tập trung vào việc triển khai và công cụ mà mỗi môi trường cần và điều này phụ thuộc vào nhà cung cấp và công cụ có sẵn trong nền tảng.
Logical design for a Data Lake pipeline
Logical design of a Data Warehousing pipeline
Tùy thuộc vào các yêu cầu downstream, các thiết kế kiến trúc chung có thể được triển khai với nhiều chi tiết hơn để giải quyết một số trường hợp sử dụng. Việc triển khai theo Platform có thể khác nhau tùy thuộc vào kỹ năng phát triển và lựa chọn bộ công cụ. Sau đây là một số ví dụ về triển khai Google Cloud cho các kiến trúc data pipeline phổ biến.
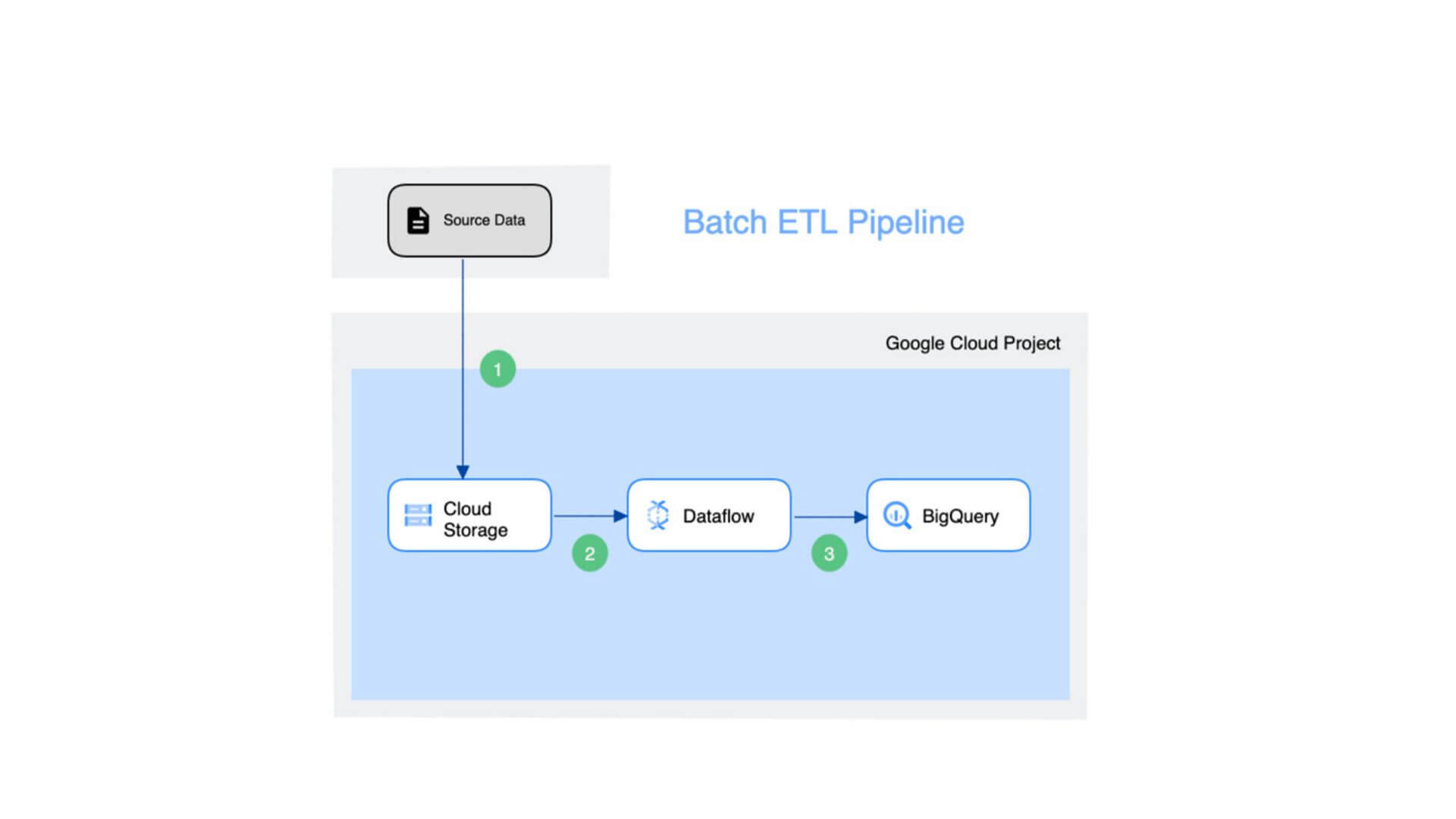
Batch ETL Pipeline
Source data có thể là các tệp cần được nhập vào công cụ phân tích Business Intelligence (BI). Cloud Storage là phương tiện truyền dữ liệu bên trong Google Cloud. Dataflow được sử dụng để tải dữ liệu vào bộ lưu trữ BigQuery đích.
Sự đơn giản của phương pháp này làm cho mẫu này có thể tái sử dụng và hiệu quả trong các quy trình chuyển đổi đơn giản. Mặt khác, nếu doanh nghiệp cần xây dựng một pipeline phức tạp, thì cách tiếp cận này sẽ không hiệu quả và hiệu quả.
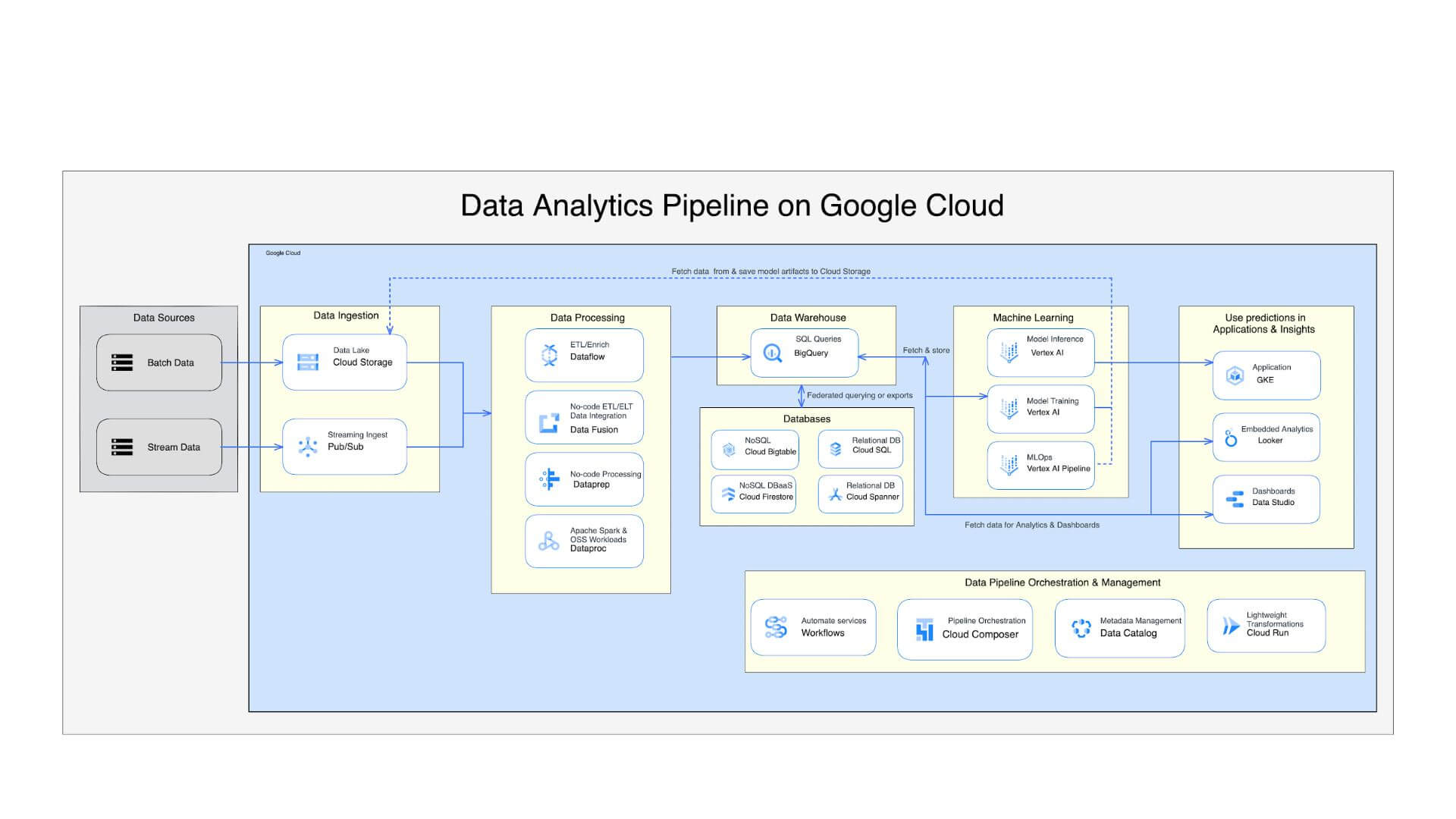
Data Analytic Pipeline
Là một quy trình phức tạp gồm cả quy trình nhập dữ liệu theo đợt và theo luồng. Quá trình xử lý rất phức tạp và gồm nhiều công cụ cũng như dịch vụ được sử dụng để chuyển đổi dữ liệu thành kho lưu trữ và điểm truy cập AL/ML để xử lý thêm.
Sự phức tạp của thiết kế có thể làm tăng thêm thời gian và chi phí của dự án nhưng để đạt được các mục tiêu kinh doanh, hãy xem xét và xây dựng cẩn thận từng thành phần.
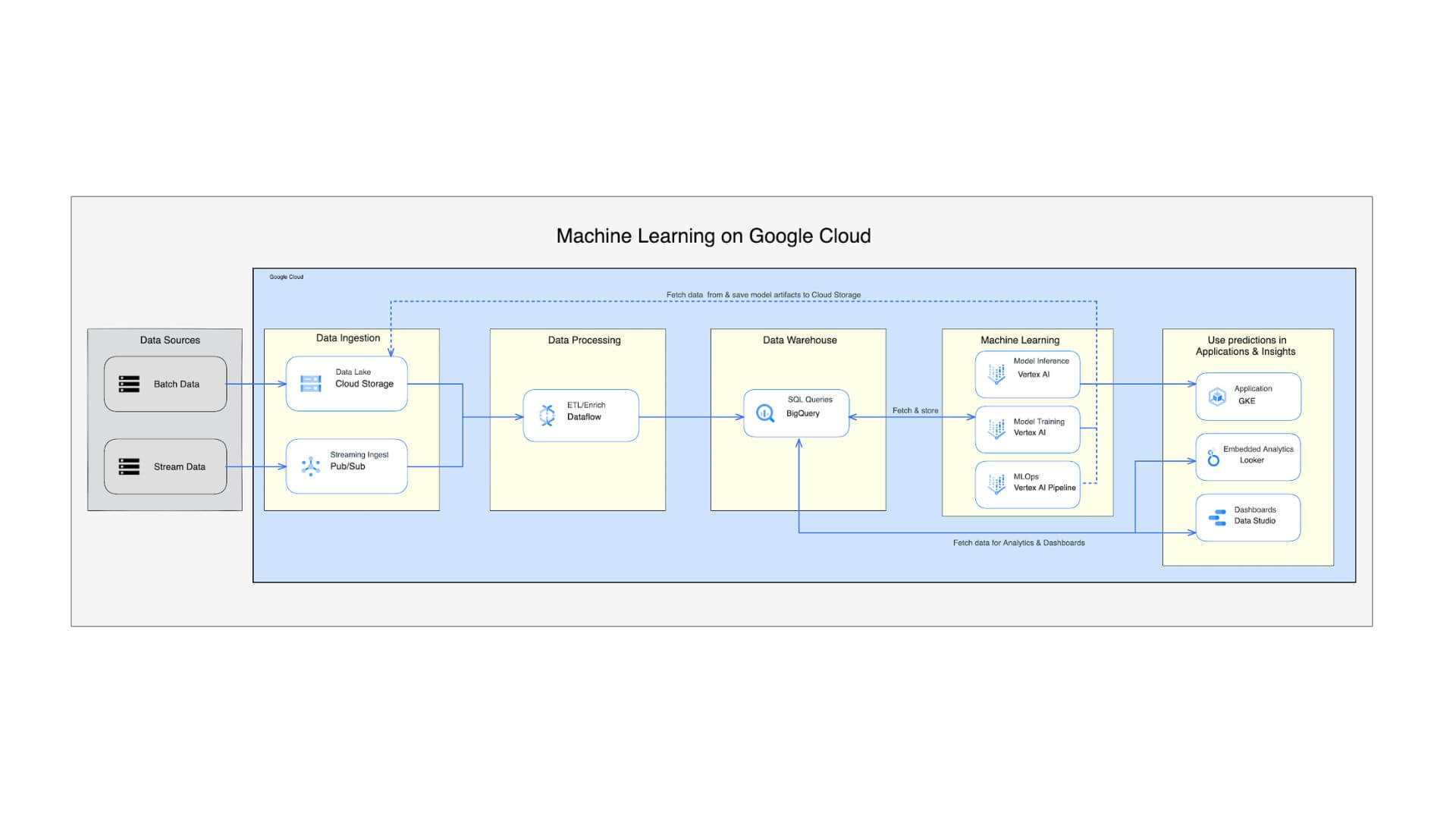
Machine Learning Data Pipeline
Là một thiết kế toàn diện cho phép doanh nghiệp sử dụng tất cả các dịch vụ gốc của Google Cloud để xây dựng và xử lý quy trình máy học.