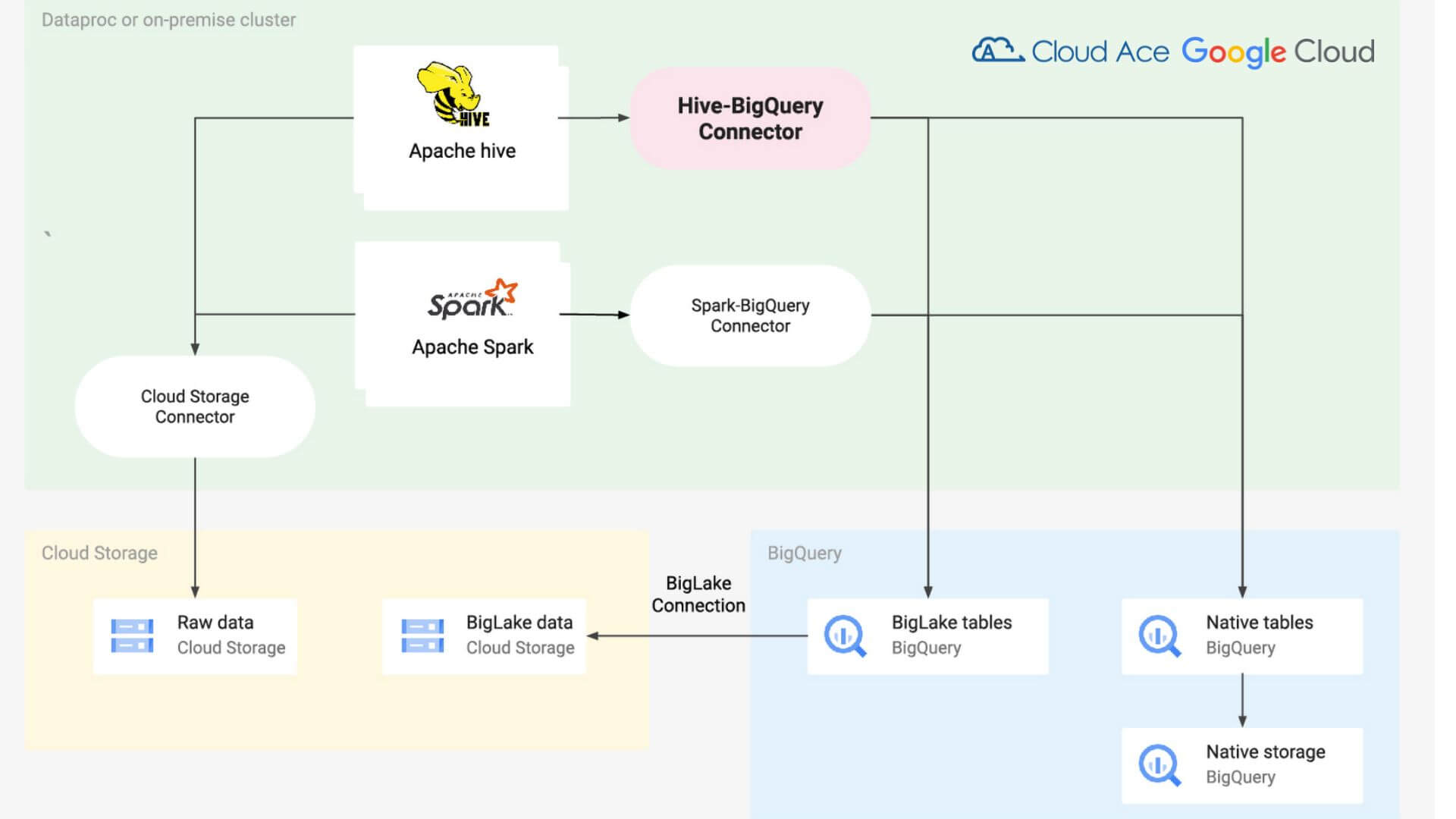
Trình kết nối Hive-BigQuery đã đóng một vai trò quan trọng trong việc cho phép các truy vấn dữ liệu BigQuery từ Hive, vì Hive là công cụ truy vấn chính trên kho dữ liệu của chúng tôi. Sự tích hợp này đã cung cấp cho Flipkart sự linh hoạt để sử dụng các công cụ truy vấn nhanh như BigQuery mà không cần sao chép dữ liệu hoặc silo trên các kho dữ liệu khác nhau.
Venkata Ramana Gollamudi, Principal Architect, Flipkart; Apache Committer